It you want to build a enterprise search engine, you don’t have to reinvent the wheel. You can use open source engines like Apache Lucene or if you have just one day to implement it Apache Solr. Solr is a full blown enterprise search server, which comes with a lot of bundled plugins like meta-data and content extraction from a very common set of document types with Apache Tika , search highlighting, fragmented search and also similarity search for search results. This is a short tutorial how to create a search application within one day.
Install Apache Solr
By the time of writing, i am using Apache Solr 3.6.0. There is a wide range of ways how you can install it. Out of the box it comes with an embedded Jetty. But if you plan to use it in production, go the way and install it on a Tomcat. See the project documentation how to do that. It is quite easy. Take care that you install the right set of plugins into your SolrHome directory.
Create a simple crawler
Solr by itself is just the search server. We need to build a crawler to feed the search server with content, and we also need to build a UI to ask the server for query results. Solr provides an API called SolrJ to connect with the server. We don’t have to deal with the content extraction, as we only need to submit the content to the server, so the crawler code is quite simple. Here is an example of a simple single threaded crawler:
/**
* Implementierung eines File System Crawlers.
*/
public class FileSystemCrawler {
private SolrServer solrServer;
private int documentProcessed;
private long processingTime;
private long volume;
private FileSystemCrawler() throws MalformedURLException {
solrServer = SolrServiceLocator.localeSolr();
}
private boolean isFileAccepted(File aFile) {
String theFilename = aFile.getName().toLowerCase();
return theFilename.endsWith(".doc") || theFilename.endsWith(".docx")
|| theFilename.endsWith(".pdf") || theFilename.endsWith(".msg")
|| theFilename.endsWith(".ppt") || theFilename.endsWith(".pptx");
}
public synchronized void notifyProcessingOfDocumentDone(long aDuration, long aVolume) {
documentProcessed++;
processingTime += aDuration;
volume += aVolume;
System.out.println(documentProcessed + " Documents processed, total time " +
processingTime + "ms, size of data " + (int) (volume / 1024) + "kb");
}
public void crawl(File aFile) throws IOException, SolrServerException {
if (aFile.canRead()) {
if (aFile.isDirectory()) {
System.out.println("Scanning directory " + aFile);
for (File theFile : aFile.listFiles()) {
crawl(theFile);
}
} else {
if (aFile.length() <5 * 1024 * 1024 && isFileAccepted(aFile)) {
try {
long theTime = System.currentTimeMillis();
ContentStreamUpdateRequest up
= new ContentStreamUpdateRequest("/update/extract");
up.addFile(aFile);
up.setParam("literal.id", aFile.toString());
up.setParam("uprefix", "attr_");
up.setParam("fmap.content", SolrConfig.FT_SEARCH_FIELD);
up.setAction(AbstractUpdateRequest.ACTION.COMMIT, true, true);
solrServer.request(up);
long theDuration = System.currentTimeMillis() - theTime;
notifyProcessingOfDocumentDone(theDuration, aFile.length());
} catch (Exception e) {
System.out.println("Error uploading file " + aFile + " : " + e.getMessage());
}
}
}
}
}
public void waitForComplete() throws IOException, SolrServerException {
solrServer.commit();
}
public static void main(String[] args) throws IOException, SolrServerException {
FileSystemCrawler theCrawler = new FileSystemCrawler();
theCrawler.crawl(new File("C:\\"));
theCrawler.waitForComplete();
}
}This will crawl your local hard disk and submit some files to the index using SolrJ. Quite easy, right?
Create a search user interface
I will use a very simple JSP page to query the index. It looks like google and also provides similarity search for a set of documents. Here is the source code(For security reasons the import statements where stripped, but they can be easily added by your IDE):
<html>
<head>
<title>Solr Search</title>
<style type="text/css">
a {
color: blue;
font-weight: bold;
text-decoration: underline;
}
.location1 {
font-weight: normal;
color: green;
text-decoration: none;
}
.content1 {
margin-bottom: 4mm;
}
.location2 {
color: green;
margin-left: 1cm;
text-decoration: none;
font-weight: normal;
}
.content2 {
margin-left: 1cm;
}
em {
color: #000000;
font-weight: bold;
font-style: normal;
}
.suchfeld {
text-align: center;
}
.logo {
text-align: center;
}
.error {
color: red;
}
input {
border: solid 1px gray;
}
</style>
</head>
<body>
<%
String theQueryString = request.getParameter("querystring");
if (theQueryString == null) {
theQueryString = "";
}
%>
<div class="logo"><img src="logo.png"></div>
<div class="suchfeld">
<form method="post">
<b>Suchanfrage</b>
<input name="querystring" type="text" size="100" value="<%=StringEscapeUtils.escapeHtml(theQueryString)%>">
<input type="submit" value="Suchen!">
</form>
You will find Details zur Abfragesyntax finden Sie <a href="http://lucene.apache.org/core/3_6_0/queryparsersyntax.html"
target="_blank">hier</a>
<br/><br/>
</div>
<%
try {
if (theQueryString.length()> 0) {
SolrServer solr = SolrServiceLocator.localeSolr();
SolrQuery theQuery = new SolrQuery();
theQuery.setRows(50);
theQuery.setStart(0);
theQuery.setHighlight(true);
theQuery.setHighlightSnippets(5);
theQuery.addHighlightField(SolrConfig.FT_SEARCH_FIELD);
theQuery.setQuery(SolrConfig.FT_SEARCH_FIELD + ":(" + theQueryString + ")");
theQuery.add("mlt","true");
theQuery.add("mlt.fl",SolrConfig.FT_SEARCH_FIELD);
QueryResponse theResponse = solr.query(theQuery);
NamedList<Object> theMoreLikeThis = (NamedList<Object>) theResponse.getResponse().get("moreLikeThis");
%>
Die Suche wurde in <%=theResponse.getElapsedTime()%>ms ausgef&uuml;hrt.<br/><br/>
<%
Map<String, Map<String, List<String>>> theHighlighting = theResponse.getHighlighting();
int docCount = 0;
for (SolrDocument theDocument : theResponse.getResults()) {
String theId = (String) theDocument.getFieldValue(SolrConfig.DOCUMENT_ID);
int p = theId.lastIndexOf('\\');
String theFilename = theId.substring(p + 1);
StringBuffer theHighlightedText = new StringBuffer();
Map<String, List<String>> theHighlight = theHighlighting.get(theId);
for (Map.Entry<String, List<String>> theEntry : theHighlight.entrySet()) {
if (theEntry.getKey().equals(SolrConfig.FT_SEARCH_FIELD)) {
for (String theValue : theEntry.getValue()) {
theHighlightedText.append(theValue);
theHighlightedText.append(" ");
}
}
}
%>
<b><a href="file:///<%=theId.replace(":","|").replace("\\","/")%>" target="_blank"><%=theFilename%>
</a></b><br/>
<a href="file:///<%=theId.replace(":","|").replace("\\","/")%>" target="_blank" class="location1"><%=theId%></a>
<div class="content1"><%=theHighlightedText%></div>
<%
List<SolrDocument> theMoreLikeThisDocuments = (List<SolrDocument>)theMoreLikeThis.getVal(docCount);
for (SolrDocument theSingleDocument : theMoreLikeThisDocuments) {
theId = (String) theSingleDocument.getFieldValue(SolrConfig.DOCUMENT_ID);
p = theId.lastIndexOf('\\');
theFilename = theId.substring(p + 1);
%>
<a href="file:///<%=theId.replace(":","|").replace("\\","/")%>" target="_blank" class="location2"><%=theId%></a><br/>
<%
}
%>
<br/><br/><br/>
<%
docCount++;
}
}
} catch (Exception e) {
%>
<br/><br/>
<div class="error"><%=e.getMessage()%><br/>
<pre><% e.printStackTrace(new PrintWriter(out));%></pre>
</div>
<%
}
%>
</body>
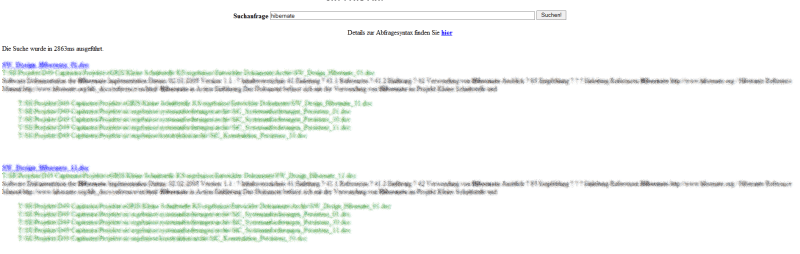
</html>The result
Here is an example of our crawler and the ui in action. Looks quite nice, right? You will get a list of found documents. You will also see the Solr MoreLikeThis Feature in action. For every found result, a set of documents which are “similar” to this one are also displayed. Using MoreLikeThis, you can also detect duplicate files.