
I saw a lot of IT projects in the past. Some of them were pretty good designed, others were really bad. Based on these experiences, I want to write a bit about an example project, and I also want to show how an example project can be modeled with UML and what would happen if we apply Domain-driven Design principles to the model.
Before you continue, you should read the books “Domain-driven Design” by Eric Evans and “Implementing Domain-driven Design” by Vaughn Vernon. Most of this example is based on their work and if you want to dive deeper into Domain-driven Design, their books are a must to read.
Requirements
A company provides IT Body Leasing. They have some Employees, and also a lot of Freelancers as Subcontractors. Currently, they use Excel sheets to manage their Customers, Freelancers, Timesheets and so on. The Excel solution does not scale well. It is not multi-user ready and also does not provide security and audit logs. So they decided to build a new web based solution. Here are the core requirements:
A searchable catalog of Freelancer must be provided
The new solution must allow to store the different Communication Channels available to contact a Freelancer
A searchable catalog of Projects must be provided
A searchable catalog of Customers must be provided
The Timesheets for the Freelancers under contract must be maintained
Based on these requirements the development team decided to model everything using UML to get a big picture of the new solution. Now let’s see what they did.
The Big Picture
Ok, here is what they designed in the first run:
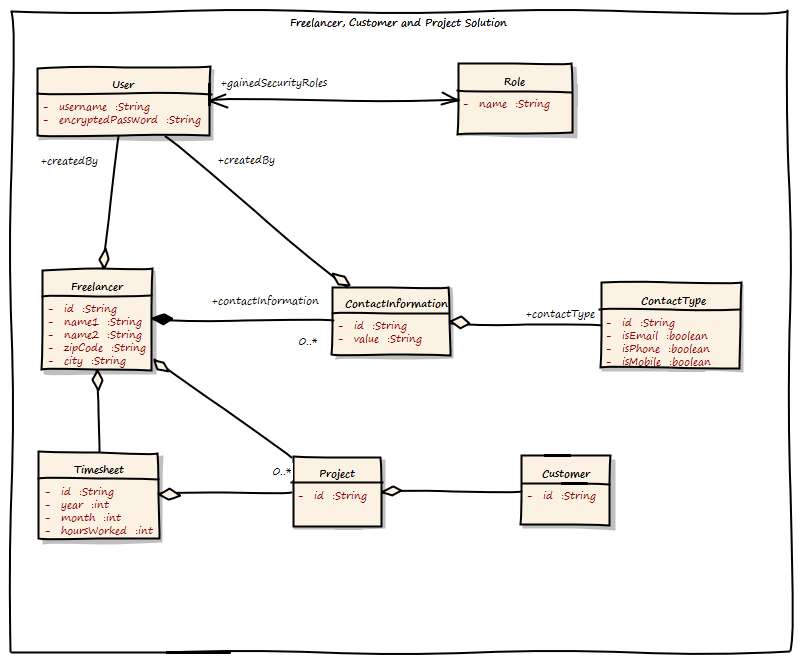
This is pretty straight forward. There are Customers, Freelancers, Projects and Timesheets. There is also a kind of user management to support role based security. But wait, something is wrong here. There are some well hidden design flaws. Can you see them? Here they are:
It is a very big object graph. If they do not use Hibernate/ JPA lazy loading here, it will pretty sure run out of memory under heavy load
Why is the association between User and Role bi-directional?`
The ContactType has some boolean flags to show what type is it, email, phone, mobile
The Freelancer class holds a list of Projects. This also means that Projects cannot be added without modifying the Freelancer object. This can cause transaction failure under heavy load, as possibly multiple users are adding Projects for the same Customer.
What does ContactInformation mean? The requirements stated “Communication Channel”. Is it the same?
The whole model seems to be more a kind of Entiy-Relationship-Diagram instead of a software model. Also, were is the business logic? The team wanted to create some Business-Services around the model to store and retrieve data, the Entities are just POJOs managed by JPA.
The hole solution is a big code smell, an anemic domain model. The team does this recognize, too. But what can be the solution? Well, a senior team member suggested to use Domain-driven Design principles to model the solution. Ok, now let’s see how DDD can improve the design.
The DDD way
Before we start in deep to look at Domain-driven Design, we should talk a little about the principles behind DDD.
One principle behind DDD is to bridge the gap between domain experts and developers by using the same language to create the same understanding. Another principle is to reduce complexity by applying object oriented design and design patters to avoid reinventing the wheel.
But what is a Domain? A Domain is a “sphere of knowledge”, for instance the business the company runs. A Domain is also called a “problem space”, so the problem for which we have to design a solution.
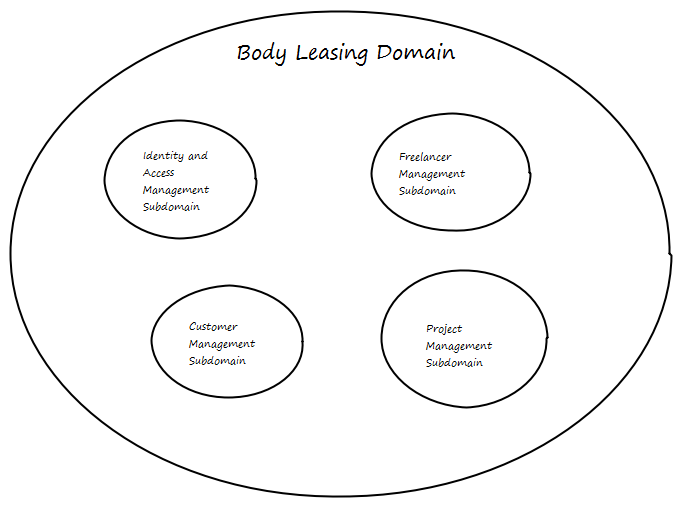
Ok, let’s look at the requirements. We could think that there is a “Body Leasing” Domain, and that is completely right. But if we look deeper into the Domain, we see something that is called “Subdomain”. The following Subdomains might be possible:
Identity and Access Management Subdomain
Freelancer Management Subdomain
Customer Management Subdomain
Project Management Subdomain
Ahh! We can split the big problem into smaller ones. This can help us to design a better solution.
The separated Domain can easily be visualized. In DDD terms this is called a Context Map, and it is the starting point for any further modeling.
Now we need to align the Subdomain aka problem space to our solution design, we need to form a solution space. A solution space in DDD lingo is also called a Bounded Context, and it is the best to align one problem space/Subdomain with one solution space/Bounded Context.
Building blocks
The building blocks of Domain-driven Design are split into tactical and strategical patterns. I wrote an Article about DDD building blocks so if you want to dive deeper please visit this article.
Please note that the following architecture patterns and class diagrams are not technology dependent. This solution can be implemented using Java SE/EE, C# or even JavaScript. It does not matter, we can archive the same benefit with every target technology.
The new Big Picture
Ok, now let’s see the new big picture of the domain model:
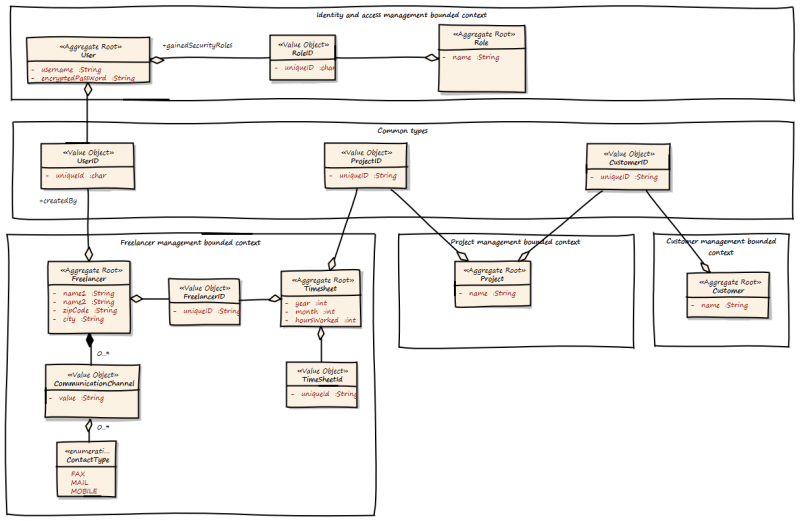
Okay, what happened here? There are now Bounded Contexts for every identified Subdomain. The Bounded Contexts are isolated, they know nothing of each other. They are only glued together by a set of common types, like UserId, ProjectId and CustomerId. In DDD this set of common types is called a “Shared Kernel”. We can also see what is part of the "Core domain" and what is not. If a bounded context is part of the problem we are trying to solve and cannot be replaced by another system, it is part of the "Core domain". If it can be replaced by another system, it is a "Generic Subdomain". The "Identity and access management" context is a "Generic Subdomain", as it could be replaced by an existing IAM solution, such as Active Directory or something else.
We applied a set of tactical and strategical patterns to the model. These patterns help us to build a better model, improve fault tolerance and also to increase maintainability.
Within each Bounded Context there are Aggregates and Value Objects. Aggregates are object hierarchies, but only the root of the hierarchy is accessible from outside of the Aggregate. Aggregates take care of business invariants. Every access to the object tree must go thru the Aggregate and not over one element within. This greatly increases encapsulation.
Aggregates and Entites are things with an unique id in our model. Value Objects are not things, they are values or measures, like a UserId. Value Objects are designed to be immutable, they cannot change their state. Every state changing method returns a new instance of the value Object. This helps us to eliminate unwanted side effects.
Designing behavior
Let’s design some behavior, the “Freelancer moved to new location” use case. Without DDD in mind, we could create a simple POJO as follows:
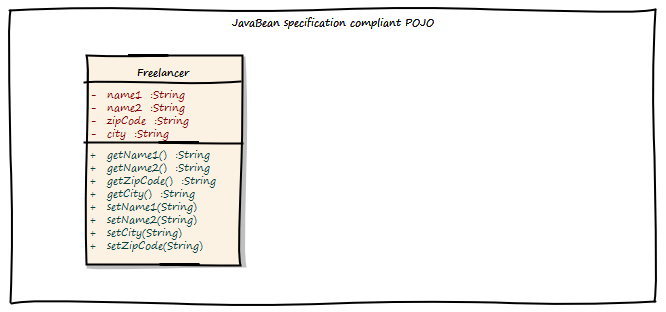
We can change the name of the Freelancer by calling the setter of the instance. But wait! Where is our use case? The setter might be called from other places. And implementing role based security might become cumbersome. as we do not have the invocation context when a setter is invoked. Also, there is a missing concept in this model, the Address. It is modeled in a very implicit way, just by simple properties of the Freelancer class.
By applying Domain-driven Design, we get the following:
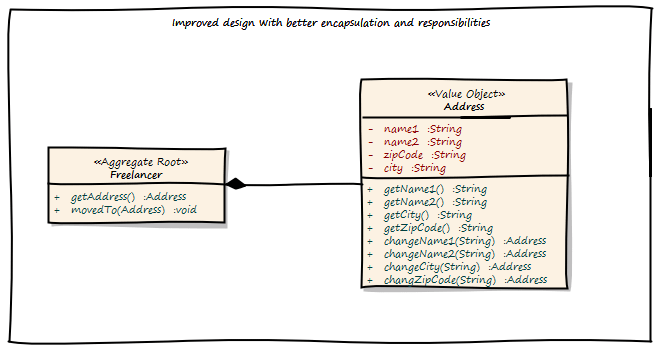
This is much better. There is now an explicit Address class, which encapsulates the whole address state. The address change use case is now explicitly modeled as a moveTo() method provided by the Freelancer aggregate. We can only change the Freelancer state by using this method. And of course this method can easily be secured by some kind of security model.
A complete Use Case and Persistence
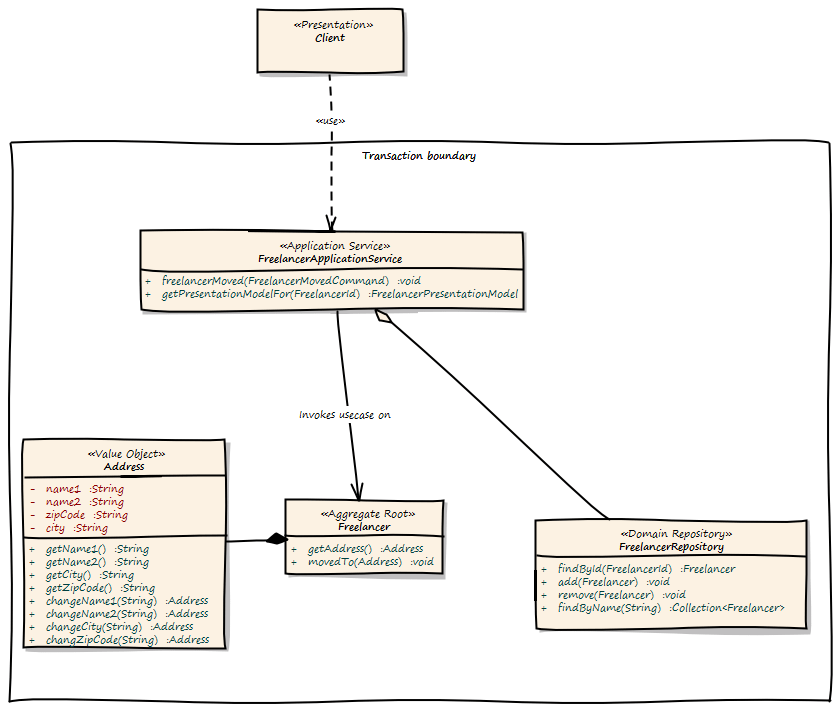
Ok, we continue to model the “freelancer moved to new location” use case. First of all, we need a kind of storage for our Freelancer Aggregate. DDD calls such storage a Repository. Using a Repository, we can search a Freelancer for instance by name, load an existing Freelancer by Id, remove it from Storage or add a new Freelancer to the storage. As a rule of thumb, there should be one Repository for every type of Aggregate. Please note that a Repository is an interface described in business terms. We will talk about the implementation in the next chapter.
The following diagram shows the modeled use case. You will see some new artifacts. First of all the user interface, the client of our domain model. A client can be everything, from JSF 2.0 front end to SOAP web services or a REST resource. So please think about the client in a general way. The client sends a command to the ApplicationService. The ApplicationService translates the command to a Domain Model use case invocation. So the FreelancerApplicationService will load the Freelancer Aggregate from the FreelancerRepository and invoke the moveTo() operation on the Freelancer Aggregate. The FreelancerApplicationService forms also the transaction boundary. Every invocation results in a new transaction. Role based security can also be implemented using the FreelancerApplicationService. It is always a good choice to keep transaction control out of the domain model. Transaction control is more a technical issue than a business thing, so it should not be implemented in the domain model.
Application Architecture
Ok, now let’s take a look at application architecture. For every Bounded Context, there should be a separate Deployment Unit. This can be a Java WAR file or an EJB JAR. This depends on your implementation technology. We designed the Bounded Context to be independent from each other, and this design goal should also be reflected in independent Deployment Units.
Every Deployment Unit contains the following parts:
A Domain Layer
An Infrastructure Layer
and an Application Layer
The Domain Layer contains the infrastructure independent domain logic as we modeled before in this example. The Infrastructure Layer provides the technology dependent artifacts, like the Hibernate based FreelancerRepository implementation. The Application Layer acts as a gateway to business logic with integrated transaction control.
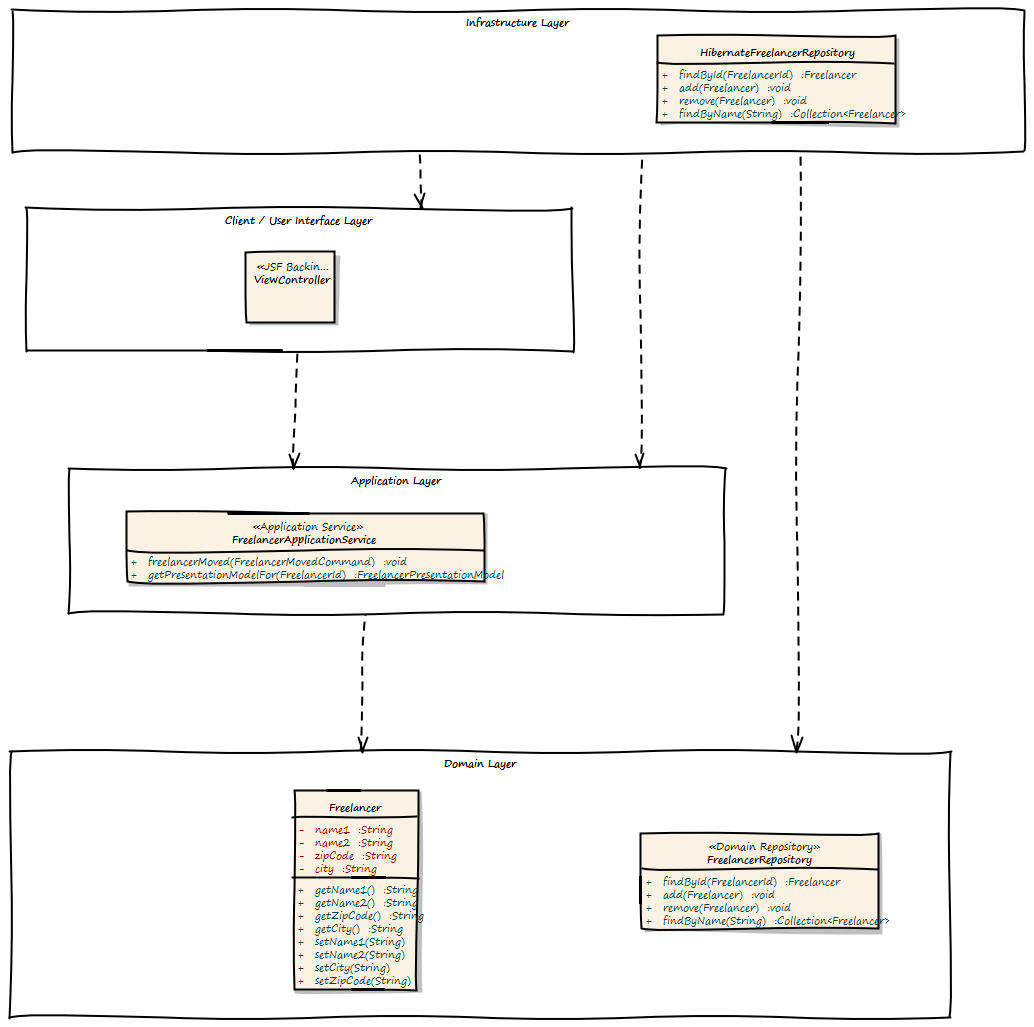
Using this style of architecture, the Domain Layer of our business logic does not depend on anything. We can change the Repository implementations from Hibernate to JPA or even NoSQL ones like Riak or MongoDB for instance without affecting any business logic.
Domain Layer
The Domain Layer contains the real business logic, but does not contain any infrastructure specific code. The infrastructure specific implementation is provided by the Infrastructure Layer. The Domain Model should be designed as described by the CQS(Command-Query-Separation) principle. There can be query methods which do just return data without affecting state, and there are command methods, which affect state but do not return anything.
Application Layer
The Application Layer takes commands from the User Interface Layer and translates these commands to use case invocations on the domain layer. The Application Layer also provides transaction control for business operations. The application layer is responsible to translate Aggregate data into the client specific presentation model by a Mediator or Data Transformer pattern.
Infrastructure Layer
The Infrastructure Layer provides the infrastructure dependent parts for all other layers, like a Hibernate or JPA backed implementation. Aggregate data can be stored in an RDMBS like Oracle or MySQL, or it can be stored as XML/JSON or even Google ProtocolBuffers serialized objects in a key-value or document based NoSQL engine. This is up to you, as long the storage provides transaction control and guarantees consistency. Infrastructure can be best described as “Everything around the domain model”, so databases, file system resources or even Web Service consumers if we interact with other systems.
Client / User Interface Layer
The Client Layer consumes Application Services and invokes business logic on these services. Every invocation is a new transaction.
The Client Layer can be almost anything, starting from an JSF 2.0 Backing Bean as the view controller to a SOAP web service endpoint or a RESTful web resource. Even Swing, AWT or OpenDolphin/JavaFX can be used to create the user interface.
Please take a look at Service integration at UI level with server side includes(SSI) to get an idea.
Context Integration
Now I want to write about Context Integration. What is this all about? Consider the following requirements of the body leasing domain:
A Customer can only be deleted if there is no Project assigned
Once a Timesheet is entered, the Customer needs to be billed
Synchronous Integration
Let’s start with the first one. In this case, the Customer Management Bounded Context needs to check if there is a Project registered for a given Customer before a Customer can be deleted. This requires a kind of Synchronous Integration of the two Bounded Contexts.
There are a lot of opportunities. First of all, we want to keep the context independent of each other. So how can we deal with that? Here is a design for the customer Bounded Context to interact with the Project Management Bounded Context:
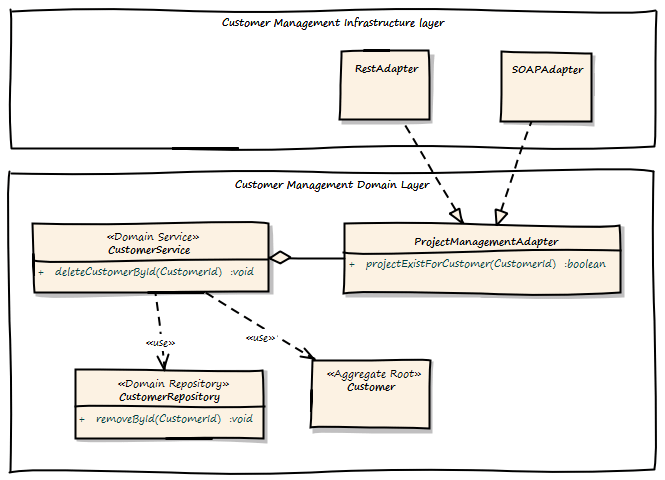
There is a new term: a Domain Service. What is a Domain Service? A Domain Service implements business logic which cannot be implemented by an Entity, Aggregate or ValueObject, because it does not belong there. For instance if the business logic invocation includes operation across multiple Domain Objects or in this case integration with another Bounded Context.
The ApplicationService invokes the deleteCustomerById method of the CustomerService. The CustomerService asks the ProjectManagementAdapter by calling customerExists() if a Project exists for the given CustomerId. Only if it returns false, the Customer is removed from the CustomerRepository.
There are two implementations of ProjectManagementAdapter available, a SOAP and a REST based one. We can either use SOAP to invoke a full web service operation with XML marshalling and using the full JAX-WS stack, or we could use REST and call http://example.com/customers/customerId/projects and get a 404(not found) or 20x(Ok) HTTP response code. This is up to you, but the REST one would be less complicated, easier to integrate and also scales better. Also we can start with REST and switch to SOAP if it is required. It is quite easy to change the implementation without affecting the domain layer, we just use another implementation of the adapter.
At the Project Management Bounded Context side, there is an ApplicationWebService exposed as a REST resource or SOAP service implementing the server part of the communication. This service or resource delegates to the ProjectApplication Service, which delegates to ProjectDomainService asking if there is a Project registered for a given CustomerId.
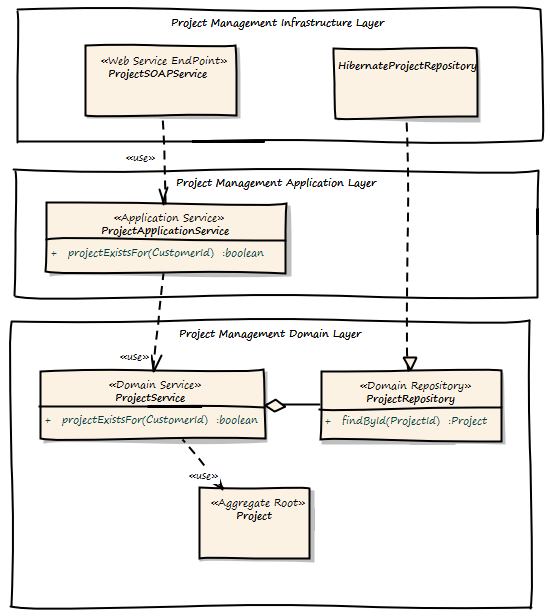
In any case we have to take care of transaction boundaries. Web Service or REST resource invocation do not promote transactions out of the box, and using XA/two-phase-commit would increase complexity and reduce scalability. It would be the best to not delete a customer physically and instead mark it as logically deleted. In case of transaction failure or concurrency issues it would be easy to restore the customer to its original state.
Here you see also the reason why the Infrastructure Layer is located above all others. It must be able to delegate to it or implement technology specific artifacts based on interfaces defined in layers below.
An asynchronous example
Ok, now we continue with a more complex example. Consider the requirement, that once a Timesheet is entered, a Customer needs to be billed.
This is a very interesting one. It is interesting because it does not require synchronous invocation. The bill can be sent just in time, or a few hours later or at the end of the month together with other bills. Or the bill can be enriched by the Customer’s Key Account Manager or whatever, the Freelancer management context just does not care.
How can we model this with DDD patterns? The key here is the phrase “once a Timesheet is…”, this is a business relevant Event in our domain, and such Events can be modeled as Domain Events!
A Domain Event is created and forwarded to an Event Store and stored there for further processing. The EventStore is part of the Bounded Context Deployment Unit and storing the Event in the store is done under the running transaction managed by an ApplicationService. At infrastructure side, there is a Timer forwarding the stored Events to the final messaging infrastructure, for instance JMS or AMQP based, even invocation of a REST resource can be considered as message delivery.
So why do we need the local EventStore? Well, the messaging infrastructure might become unavailable temporarily, but this should not affect our running Bounded Context. So the Events will be queued and delivered when the infrastructure is available again. If we would couple the messaging infrastructure directly with the Event producer, the producer might fail to send in case of an infrastructure error. Even if we use messaging, this might case a ripple effect over the whole infrastructure if something goes wrong, and this is the reason we use messaging: system decoupling
Here is how the Freelancer Management Bounded Context is modeled:
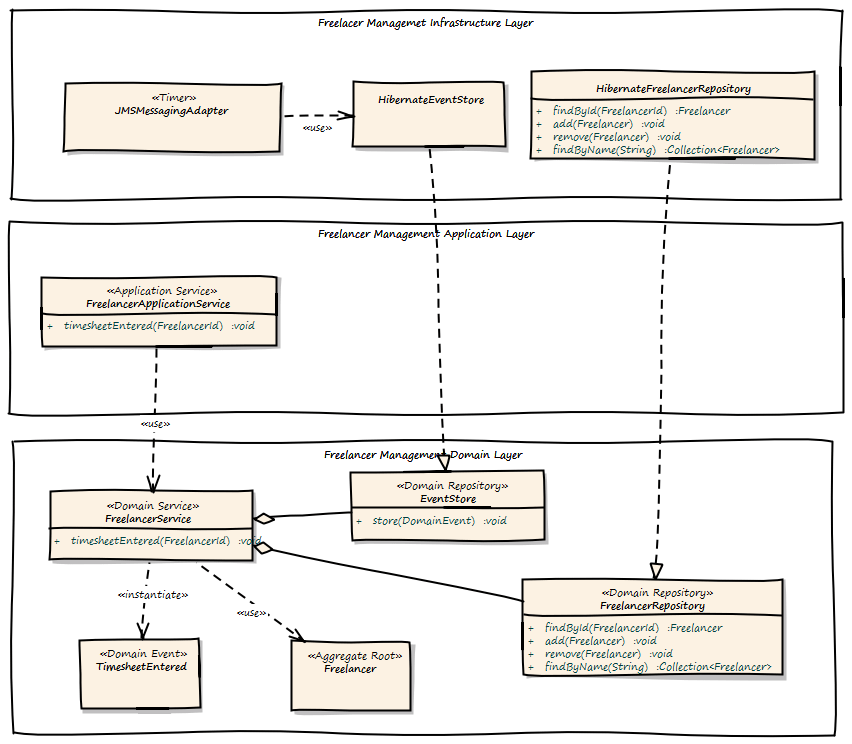
The FreelancerService creates a TimesheetEntered Domain Event and forwards it to the EventStore, which is basically another Repository. Then, the JMSMessagingAdapter takes the pending Events from the EventStore and tries to forward them to the target messaging infrastructure till delivery succeeds. But this forwarding is handled in another transaction, and can be triggered by a timer, for instance.
Ok, how does the Customer Management Context handle the Events? This is modeled as follows:
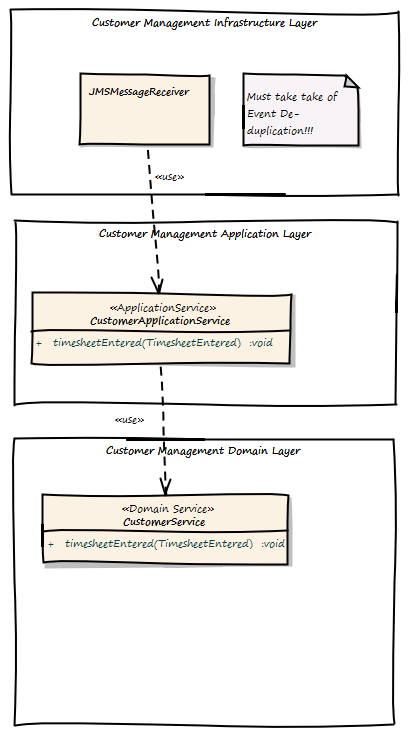
Again, the Infrastructure Layer must be located all other layers as it must in case of context integration invoke the application service.
Here is the origin the JMSMessageReceiver located in the infrastructure layer. The MessageReceiver is also responsible for Event de-duplication. This can happen in case of system failure, when already delivered Events are redelivered or something else went wrong. Since the Infrastructure Layer is located above the Application Layer, it can invoke the CustomerApplicationService, which itself calls the CustomerService, which implements the business logic to send a bill.
In this scenario, the transaction boundaries are at the ApplicationService. We can argue that the JMSMessageReceiver might call the CustomerService, and do it around a JMS Transaction. This is also a viable solution.
The tricky part is Event de-duplication. This can happen in case of infrastructure failure or system outage. This can be avoided by giving every Event an unique id, and track which ids were already processed.
Another tricky part is Event ordering. This depends on the messaging infrastructure. If the infrastructure supports Event ordering, everything is alright. If not, this must be implemented by ourselves. In any case it is a good practice to design Events as an idempotent operation. This means that every Event can be processed multiple times, and every time with the same result without unwanted side effects.
Query data from multiple Bounded Contexts or Aggregates
Sometimes we need to collect data spread over multiple Aggregates or even Bounded Contexts. This can be a tough task. Within one Bounded Context we could use specialized database views and retrieve data using Hibernate or JPA, but getting data spread over multiple Bounded Contexts can lead to a lot of remote method invocations and other issues; this solution might not scale well. We have also to consider that using a view might break the business invariance of a well designed Aggregate. This is an issue we really have to take care of!
Now, what might be a solution? We can think about CQRS or Command-Query Responsibility Segregation! Basically we divide the model into a command model, which contains business logic, and a query model, which is used to retrieve data. So for this example, the command model would consist of all the Bounded Contexts we want to query, and a query model, which is used to query aggregated data(and is optimized to query data effectively). The command model and query model are synchronized using Domain Events! Once a business operation is triggered in the command model, a Domain Event is issued and processed by the Query Model, and the data is updated.
Using CQRS, we can design high performance data processing systems and also integrating with Business Intelligence is no problem anymore. Think about it: the query model can basically be a data warehouse.
Final words
I really like the idea behind Domain-driven Design. Using this technique, even very complex domain logic can be easily distilled and modeled. This leads to better systems, improved user experience and also more reliable and maintainable solutions. Thanks to Eric Evans and Vaughn Vernon! DDD / Domain-driven Design is object oriented programming done right.